
简介
如果一个事务中含有X,则该事务中很可能含有Y。具体形式为{X}→{Y},即通常可以描述为:当一个事务中顾客购买了一样东西{钢笔}(这里X=“钢笔”),则很可能他同时还购买了{墨水}(这里Y= "墨水"),这就是关联规则。
关联规则的目的在于在一个数据集中找出项之间的关系,也称之为购物蓝分析 (market basket analysis)。例如,购买鞋的顾客,有10%的可能也会买袜子,60%的买面包的顾客,也会买牛奶。这其中最有名的例子就是"尿布和啤酒"的故事了。
先验算法[1]是关联式规则中的经典算法之一。在关联式规则中,一般对于给定的项目集合(例如,零售交易集合,每个集合都列出的
单个商品的购买信息),算法通常尝试在项目集合中找出至少有C个相同的子集。先验算法采用自底向上的处理方法,即频繁子集每次只扩展一个对象(该步骤被称为候选集产生),并且候选集由数据进行检验。当不再产生符合条件的扩展对象时,算法终止。
相关定义
设: I={i1,i2......,im}是所有项目的集合, D是所有事务的集合(即数据库),每个事务T是一些项目的集合,T包含在I中, 每个事务可以用唯一的标识符TID来标识。 设X为某些项目的集合,如果X包含在T中,则称事务T包含X,关联规则则表示为如下形式(X包含在T)=>(Y包含在T)的蕴涵式,这里X包含在I中,Y包含在I中,并且X∧Y=Φ。 其意义在于一个事务中某些项的出现,可推导出另一些项在同一事务中也出现。这里将(X包含在T)=>(Y包含在T)表示为X=>Y,这里,‘=>’称为‘关联’操作, X称为关联规则的先决条件,Y称为关联规则的结果。
事务集D中的规则X=>Y是由支持度s(support)和置信度c(confidence)约束,置信度表示规则的强度, 支持度表示在规则中出现的频度。
规则X=>Y的支持度s定义为: 在D中包含X∪Y的事务所占比例为s%, 表示同时包含X和Y的事务数量与D的总事务量之比; 规则X=>Y的置信度c定义为: 在D中,c%的事务包含X的同时也包含Y, 表示D中包含X的事务中有多大可能性包含Y。
最小支持度阈值minsupport表示数据项集在统计意义上的最低主要性。 最小置信度阈值mincontinence表示规则的最低可靠性。 如果数据项集X满足X。support>=minsupport, 则X是最大数据项集。 一般由用户给定最小置信度阈值和最小支持度阈值。
置信度和支持度大于相应阈值的规则称为强关联规则, 反之称为弱关联规则。 发现关联规则的任务就是从数据库中发现那些置信度、支持度大小等于给定值的强壮规则。
Apriori算法描述
在Apriori算法中,寻找最大项目集的基本思想是: 算法需要对数据集进行多步处理.第一步,简单统计所有含一个元素项目集出现的频率,并找出那些不小于最小支持度的项目集, 即一维最大项目集. 从第二步开始循环处理直到再没有最大项目集生成. 循环过程是: 第k步中, 根据第k-1步生成的(k-1)维最大项目集产生k维侯选项目集, 然后对数据库进行搜索, 得到侯选项目集的项集支持度, 与最小支持度比较, 从而找到k维最大项目集.
算法图例说明
假设有一个数据库D,其中有4个事务记录,分别表示为:
| T1 | I1,I3,I4 |
| T2 | I2,I3,I5 |
| T3 | I1,I2,I3,I5 |
| T4 | I2,I5 |
这里预定最小支持度minSupport=2,下面用图例说明算法运行的过程:
| T1 | I1,I3,I4 |
| T2 | I2,I3,I5 |
| T3 | I1,I2,I3,I5 |
| T4 | I2,I5 |
扫描D,对每个候选项进行支持度计数得到表C1:
| {I1} | 2 |
| {I2} | 3 |
| {I3} | 3 |
| {I4} | 1 |
| {I5} | 3 |
比较候选项支持度计数与最小支持度minSupport,产生1维最大项目集L1:
| {I1} | 2 |
| {I2} | 3 |
| {I3} | 3 |
| {I5} | 3 |
由L1产生候选项集C2:
| {I1,I2} |
| {I1,I3} |
| {I1,I5} |
| {I2,I3} |
| {I2,I5} |
| {I3,I5} |
扫描D,对每个候选项集进行支持度计数:
| {I1,I2} | 1 |
| {I1,I3} | 2 |
| {I1,I5} | 1 |
| {I2,I3} | 2 |
| {I2,I5} | 3 |
| {I3,I5} | 2 |
比较候选项支持度计数与最小支持度minSupport,产生2维最大项目集L2:
| {I1,I3} | 2 |
| {I2,I3} | 2 |
| {I2,I5} | 3 |
| {I3,I5} | 2 |
由L2产生候选项集C3:
| {I2,I3,I5} |
扫描D,对每个候选项集进行支持度计数:
| {I2,I3,I5} | 2 |
比较候选项支持度计数与最小支持度minSupport,产生3维最大项目集L3:
| {I2,I3,I5} | 2 |
算法终止。
例子
一个大型超级市场根据最小存货单位(SKU)来追踪每件物品的销售数据。从而也可以得知哪里物品通常被同时购买。通过采用先验算法来从这些销售数据中建立频繁购买商品组合的清单是一个效率适中的方法。假设交易数据库包含以下子集{1,2,3,4},{1,2},{2,3,4},{2,3},{1,2,4},{3,4}。每个标号表示一种商品,如“黄油”或“面包”。先验算法首先要分别计算单个商品的购买频率。下表解释了先验算法得出的单个商品购买频率。
| 商品编号 | 购买次数 |
| 1 | 3 |
| 2 | 6 |
| 3 | 4 |
| 4 | 5 |
然后我们可以定义一个最少购买次数来定义所谓的“频繁”。在这个例子中,我们定义最少的购买次数为3。因此,所有的购买都为频繁购买。接下来,就要生成频繁购买商品的组合及购买频率。先验算法通过修改树结构中的所有可能子集来进行这一步骤。然后我们仅重新选择频繁购买的商品组合:
| 商品编号 | 购买次数 |
| {1,2} | 3 |
| {2,3} | 3 |
| {2,4} | 4 |
| {3,4} | 3 |
并且生成一个包含3件商品的频繁组合列表(通过将频繁购买商品组合与频繁购买的单件商品联系起来得出)。在上述例子中,不存在包含3件商品组合的频繁组合。最常见的3件商品组合为{1,2,4}和{2,3,4},但是他们的购买次数为2,低于我们设定的最低购买次数。
算法评价
先验算法具有显著的历史地位,它的优点是简单、易理解、数据要求低,但从算法执行过程也可以看到Apriori算法的缺点: 1)在每一步产生侯选项目集时循环产生的组合过多,没有排除不应该参与组合的元素;2)每次计算项集的支持度时,都对数据库D中的全部记录进行了一遍扫描比较,如果是一个大型的数据库的话,这种扫描比较会大大增加计算机系统的I/O开销。而这种代价是随着数据库的记录的增加呈现出几何级数的增加。因此Apriori算法中的一些低效与权衡弊端也进而引致了许多其他的算法的产生,例如FP-growth算法。候选集产生过程生成了大量的子集(先验算法在每次对数据库进行扫描之前总是尝试加载尽可能多的候选集)。并且自底而上的子集浏览过程(本质上为宽度优先的子集格遍历)也直到遍历完所有 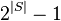 个可能的子集之后才寻找任意最大子集S。
个可能的子集之后才寻找任意最大子集S。
摘自:



相关推荐
matlab开发-关联规则挖掘的先验算法。事务数据集中关联规则挖掘的Apriori的matlab实现
同时,本文介绍了自组织特征映射网络(Self-Organizing Feature Map, SOFM)的相关内容,SOFM网络是将多维数据映射到低维规则网格中,可以有效的进行大规模的数据挖掘,其特点是速度快,但是分类的精度不高。而K-均值聚类...
贝叶斯分析方法(Bayesian Analysis)提供了一种计算假设概率的方法,这种方法是基于假设的先验概率、给定假设下观察到不同数据的概率以及观察到的数据本身而得出的。其方法为,将关于未知参数的先验信息与样本信息...
为提高频繁项集的产生效率, 提出一种在垂直数据表示下, 基于先验位运算的频繁项集挖掘算法(A-FIMBII)。该算法建立从项集合到事务的索引, 利用先验性质减少候选集的产生, 通过位运算计算支持度。与Apriori、Eclat...
综述了不同分类算法的思想和特性, 决策树分类算法能够很好地处理噪声数据, 但只对规模较小训练样本集有效; 贝叶斯分类算法精度高、 速度快, 错误率低, 但分类不够准确;传统的基于关联规则算法分类准确率高, ...
使用WHO历史数据通过聚类和FP-增长算法学习高登革热发病率 这是第三届IEEE国际代理大会(ICA 2018)上的被接受的论文 抽象的 ...先验算法 生成关联规则 rules = Apriori.generate_itemsets_rules(da
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。算法的名字基于这样的事实: 算法使用频繁项 集性质的先验知识。Apriori使用一种称作逐层搜索的选代方法,k- 项集用于探索(k+1)- 项集。首先,找出频繁1...
数据挖掘导论(完整版)(全面介绍数据挖掘的理论和方法)基本信息原书名: Introduction to Data Mining原出版社: Addison Wesley作者: (美)Pang-Ning Tan Michael Steinbach Vipin Kumar译者: 范明 范宏建丛书名: ...
针对当前算法从加权项事务数据库挖掘频繁加权项集(FWI...相比基于先验的算法,算法平均可节省99.37%的耗时;相比基于位矩阵的加权频繁项集生成算法,提出的算法可节省99.06%的耗时,明显提升了频繁加权项集挖掘效率。
先验法关联规则挖掘综述以及其实现先验法关联规则挖掘综述以及其实现先验法关联规则挖掘综述以及其实现先验法关联规则挖掘综述以及其实现先验法关联规则挖掘综述以及其实现
先验的Apriori 算法的实现 - 数据挖掘 2015.1 - UEFS
一种新的高效Apriori算法,李新征,,Apriori算法是关联规则挖掘中的经典算法。本文针对Apriori算法的瓶颈提出一种使用先验算法产生频繁2项目集。并给出了一种简单有效的逐
局部异常因子检测算法(Local Outlier Factor,简称LOF)是一种用于检测数据集中异常点的有效算法。它基于无监督学习的方法,不需要任何先验...GMM在许多领域都有广泛的应用,如语音识别、金融风险评估和数据挖掘等。
着重分析了自组织数据挖掘与人工神经网络方法对系统的先验知识的利用 ,算法过程以及推广能力方面的差别 ,显示了自组织数据挖掘方法具有能同时利用关于系统的先验知识和...
Apriori算法利用频繁项集性质的先验知识(prior knowledge),通过逐层搜索的迭代方法,即将k-项集用于探察(k+1)-项集,来穷尽数据集中的所有频繁项集。 先找到频繁1-项集集合L1,然后用L1找到频繁2-项集集合L2,接着...
Apriori关联规则挖掘 使用先验算法设计给定数据集的关联规则挖掘模型
productList是商品的详单,productAttribute是商品相关属性。 brandList是品牌的详单,brandAttribute是品牌相关属性。...两个sale文件是两年的购物栏数据(已经预处理好)。 可用于关联分析相关算法的学习。
决策树分类作为一种基于空间数据挖掘的知识发现的监督分类方法,它通过决策学习过程得到分类规则并对遥感影像进行分类,突破了以往分类树或分类规则的构建要利用分类者的生态学和遥感先验知识的确定。我们以AdaBoost...
1. 聚类算法 K-均值 K-means++ 一般来说,这个算法类似于K-means; 与经典的 K-means 随机选择初始质心不同,更好的初始化过程集成到K-means++中,其中远离现有质心的观测值被选为下一个质心的概率更高。 初始化过程...
决策树算法实战视频教学课程,案例与代码相结合,内容涉及1、决策树算法精讲2、决策树算法的Python实现3、对测试数据进行分类思路4、项目实战:使用决策树算法对测试数据进行分类实战。Python 在机器学习领域应用是...